Developing an AI-ready FAIR data analysis platform for experimental life science
The Franklin’s Advanced Research Computing (ARC) team has developed a robust and resilient data storage and analysis platform to ensure that all data created at the Franklin can be managed in line with the FAIR principles: to be findable, accessible, interoperable and retrievable. The infrastructure automates the transfer, cataloguing and curating of data for speed and consistency. The software developed through this work is open source and the Franklin is sharing its data management expertise with other organisations to help embed best practice widely within the research computing field.



Background
Advanced life science technologies like cryo-electron microscopy, metabolomics and proteomics generate vast volumes of heterogenous data, with the potential to offer important new insights and discoveries using machine learning. To realise this potential, the data need to be FAIR: findable, accessible, interoperable and retrievable. This requires a robust data management system. Data also require context in the form of scientific metadata. For example, a tomograph of a cell needs to have attached data that describes the instrument settings when it was acquired.
However, creating a management system to curate the data generated by researchers in the Franklin (in common with those elsewhere) posed major challenges. Data from different scientific disciplines and instruments are typically of different types and in different formats. The metadata that needs to be captured to make them usable varies between instruments and types of experiment. Moreover, to allow access to partners and collaborators while safeguarding the data, the system needs to be robust, resilient and secure. Finally, data curation and metadata capture needs to be automated as much as possible to speed up the process and ensure consistency.
This robust data management strategy offers opportunities to improve the reproducibility of our data and to better curate our data assets to make them openly available.
Science in Detail
The Franklin has been working on a FAIR data management system since the Institute’s creation. This has been built on since 2020 by the Franklin’s Advanced Research Computing team to create the system in place today.
Data generated by the instruments in use at the Franklin are written directly to a large object storage layer, which is part of the distributed data storage for CERN. This required the team to set up bespoke arrangements for each instrument, as each has unique operating software and data writing protocols.
The ARC team use Globus software to provide fast transfer of large amounts of data at speed – the Franklin generates around 70TB per month – to the data storage, cloud Virtual Machines and High-Performance Computing clusters . Some of the instruments would not easily link with Globus, creating additional complexity.
The team use a metadata catalogue through which all data is automatically mapped to allow for ease of retrieval and analysis. The team is part of SciCat, an international collaboration to create an open-source scientific metadata catalogue to enable FAIR data across the community. The Franklin is one of the SciCat community partner facilities, providing input on catalogue governance, software development and user experience.
The team have built bespoke software, called RFI File Monitor, that automatically captures the metadata that is required from each experiment. This involved a manual set up which the team are automating using a cloud native-based workflow manager. This carries out the necessary tasks sequentially to set up automated metadata capture. Once new instrument data have been transferred by Globus, it automatically captures the metadata and syncs it to SciCat.
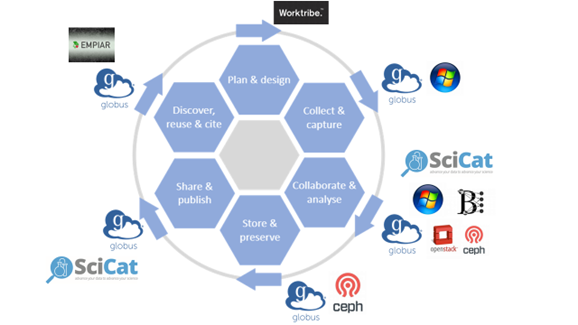
The result is a resilient and robust platform, which could be reconstructed from scratch immediately following any catastrophic failure. Everything is run through configuration management and written as code, so it can be easily scaled and restored.
Impact
The data management system provides the Franklin with the capability to do research that would otherwise not be possible. For example, data from different tomographic images cannot usually be compared, as they have been acquired and reconstructed under different measurement conditions. Substantial metadata is required to capture these conditions with sufficient information to allow for quantitative analyses of images acquired at different times or in different ways. Using the Franklin’s digital infrastructure makes this type of analysis possible.
The work by the ARC team to create the system has provided a blueprint for other organisations. This has been demonstrated as our infrastructure work has been awarded two grants through the National Federation Computing Service. With support from these awards, the Franklin is advising on the UK’s national digital infrastructure roadmap and lessons from the Franklin’s experience are helping to shape national policy in this area.
Although the systems developed are bespoke to the Franklin, they include many elements which are transferable to other organisations. Considerable interest has been shown in the Franklin’s data management infrastructure by others in the research computing field and particularly by industry partners. The Franklin’s commitment to making its underlying software open source helps to ensure that others can take advantage of its expertise and best practice in FAIR data management.
The team are modelling the application of OpenFAIR principles to major infrastructure data management and have presented their work to the research software engineering community, including at conferences such as Computer Insights UK. They also regularly talk to industry partners about the system. The team were also awarded a grant from NFCS [UKRI National Federated Compute Services NetworkPlus] to publish the research to enable its use by other organisations to enhance the value they realise from their own data.
Participation in SciCat has also enabled the team to contribute to best practice in scientific metadata management now being adopted by others. Their development of Globus technology for capturing data from instruments saw Dr Dimitrios Bellos win a 2025 award from Globus for community contribution.

Why the Franklin?
The Franklin’s partnership structure and its mix of different disciplines creating heterogenous data gave a range of specific data requirements. As a new institute, it was in the unique position of being able to incorporate FAIR principles from the start, rather than trying to adapt existing systems. This allowed for a data management approach that values both independence and integration, ensuring that each component of the systems operates effectively while contributing to the overall goals. Rather uniquely, it created the ARC team for development of research data management solutions independent of responsibilities for day-to-day IT services, allowing for a dedicated focus on organizing and maintaining research data efficiently. Additionally, the ARC team plays a crucial role in working closely with researchers by creating tools that utilize managed data to support near-term research objectives, thereby promoting adherence to best practices through practical application.
At the Franklin researchers across disciplines work closely together and there is a strong dialog between scientific domain specialists and Research Software Engineers. This engagement has led to an active “data culture” in the Franklin from which we can make an evolving platform driven by science. Good communication allows us to identify the relevant metadata therefore context to bring data together in relevant ways creating a knowledge graph of our research.
More case studies
-
![]()
Harnessing the power of citizen scientists
-
![]()
The Science and Technology Facilities Council
-
![]()
Covid-fighting llamas at the Royal Society Summer Science Exhibition
-
![]()
Quantifying membrane dynamics to gain insights into cell function
-
![]()
Using mass spectrometry imaging to understand metabolic mechanisms of disease
-
![]()
University College London