Applying artificial intelligence to accelerate the discovery of anti-viral nanobodies
Nanobodies are single domain antibodies derived from the unique heavy chain only immunoglobulins of camelids. Their rapid generation is important for pandemic preparedness as they can be used in diagnostic tests. We will use machine learning tools to accelerate the discovery of nanobodies to norovirus, which causes stomach flu.
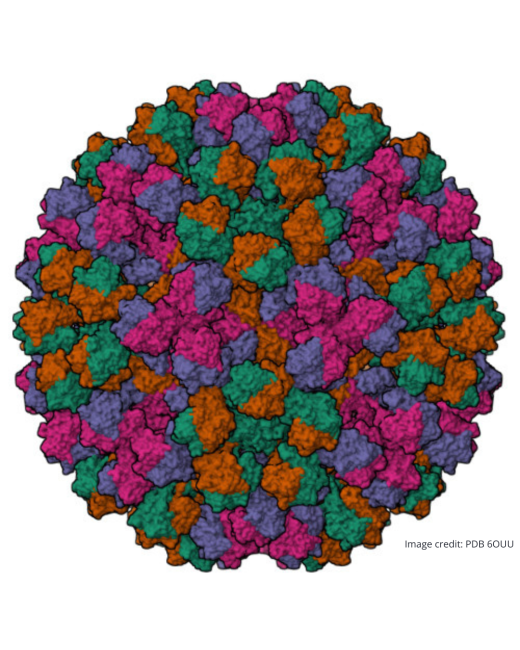
Human norovirus is a global health concern: it is the most common cause of acute gastroenteritis, leading to 200,000 deaths worldwide annually. The norovirus family is very diverse and is divided into 10 genogroups, of which only 2 are responsible for approximately 90% of all reported cases. Within each genogroup, there are many different genotypes which results in high sequence variation of viral proteins and complicates the development of rapid diagnostic tools. Since only a small number of virions are required for infection, hospitals, daycares and long-term care facilities are at high risk for outbreaks, which quickly becomes difficult to control due to the highly contagious nature of the virus.
Norovirus surveillance only occurs during outbreaks using RT-PCR or ELISA, both of which are relatively costly and time-consuming lab-based techniques, requiring a high level of operator expertise. The natural protective immune response raised during norovirus infections is limited across genogroups as well as among the genotypes in the same group and the immunological memory is typically not retained long-term. As such, there is an unmet need for reliable and easily accessible diagnostics that can detect a wide range of norovirus genotypes.
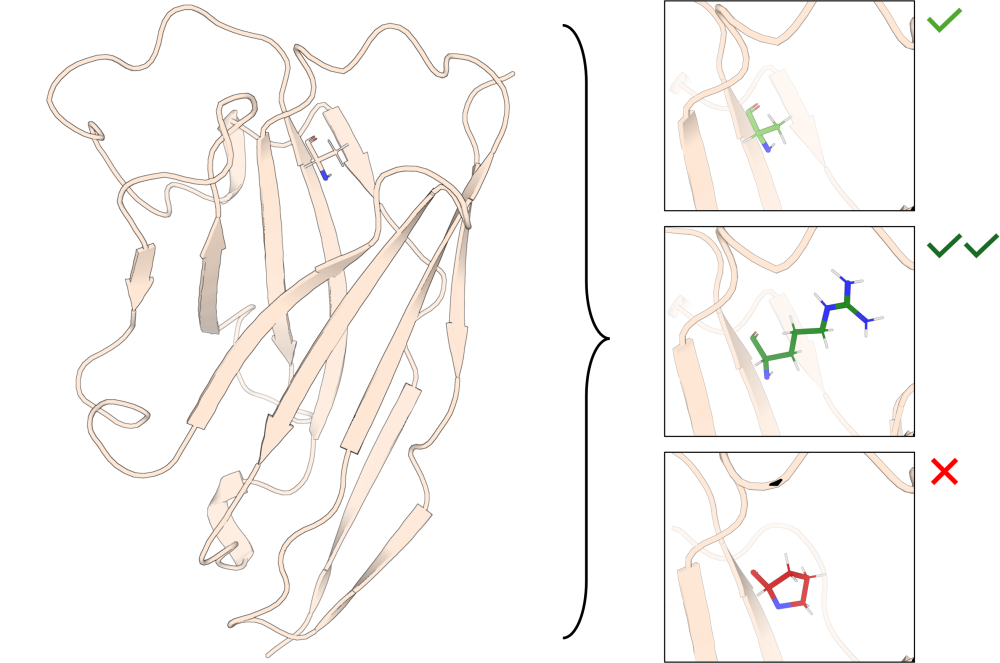
In this project, we will pursue the identification and generation of high affinity nanobodies that bind norovirus. Instead of utilising an immunised library, which is typical for nanobody discovery, we will use libraries made from llamas which have not seen norovirus proteins before (naïve libraries). Screening non-immunised (naïve) libraries overcomes the time constraints associated with immunisation, speeding up the timeline for discovery of binders. However, resulting nanobodies identified from naïve libraries have not yet undergone B cell maturation, which occurs during the immunisation process. As a result, naïve nanobodies will most likely have a low binding affinity for their target protein on the virus.
We will set out to improve the affinity of these nanobodies using a bespoke protein large language model (pLLM), developed within the Advanced Research Computing team. This pLLM will incorporate ESM2 (a generic pLLM) and will be fine-tuned using data that we have captured in our in-house AntigenApp software from historical discovery campaigns within the Nanobody Discovery Platform. Predictions will be experimentally validated and the data fed back into the pLLM to create an active learning cycle and improve overall prediction power.
Any anti-norovirus nanobodies, either low or high affinity, have the potential to be incorporated into accessible diagnostics, such as lateral flow tests, allowing for improved surveillance and better control of future outbreaks.
This project will also lay the foundation for the faster generation of high affinity nanobodies by omission of the lengthy immunisation process. If successful, in addition to reducing development time and cost, this in silico pipeline will significantly reduce animal use and human handling of dangerous pathogens. This process can be applied to emergent pathogens towards improved pandemic preparedness.


Advanced Research Computing
The Franklin develops state of the art digital infrastructure to enable cutting edge research. Our interdisciplinary research generates a variety of data structures and sizes that all need to be stored, curated and processed to give data driven insights.

Nanobodies Discovery Platform
Nanobodies are single domain antibodies derived from the unique heavy chain only immunoglobulins of camels, llamas, and alpacas.
Contact information



